Pt 4 - Predicting total NHL Team Wins with Machine Learning - 2022/23 Season
With the NHL regular season wrapped up, it's a great time to delve into the world of Machine Learning predictions for the 2022-23 NHL season. Our predictions have been carefully crafted by analyzing data from previous seasons. By comparing our predictions to actual results, we can determine the accuracy of our model and identify areas where we can improve. Overall, our predictions for 20 of the 32 teams have fallen in range of our Prediction Interval. A prediction interval is a range of values that is estimated to contain the future outcome of a particular event or measurement with a certain level of confidence. It is a statistical tool that is used to estimate the likely range of values that a future observation or measurement will fall within.
The chart at the top provides a comparison between the current total wins each team has and the average of our prediction interval. When analyzing our prediction interval, it's important to note that our forecasted Wins are based on an average of the top and bottom predictions. This means that while we predict 12 of the 32 results to fall within a +/- 5 Win range, there is still plenty of room for variability that could impact our overall accuracy. With that in mind, we can explore ways to refine our prediction model and potentially increase the number of predicted results that fall within our desired range. For example, we could look at incorporating more data sources or adjusting our weighting of different variables to better capture the nuances of our target population. By dedicating time and resources to improving our prediction accuracy, we can better position ourselves for success and drive better outcomes next season.
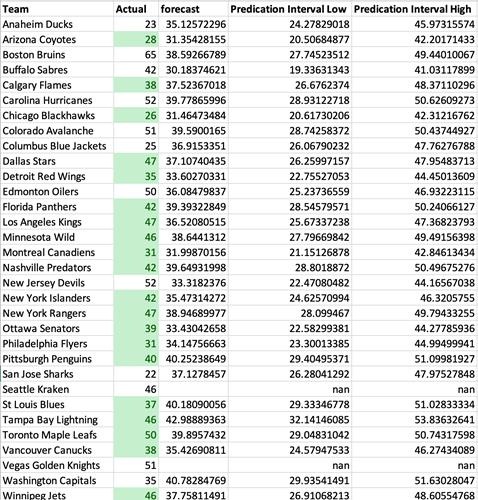
Upon closer inspection of the comparison between the prediction intervals and current standings, it becomes apparent that the majority (20) of the current Wins of the 32 teams fall within our predicted range (as indicated by the green highlights). This suggests that our predictions are fairly accurate, and that we can expect similar results for future games. However, there are still a few outliers that fall outside of our prediction intervals, which may indicate that there are other factors at play that we had not accounted for in our model. Further investigation is warranted to determine the cause of these discrepancies and to refine our model accordingly.
In addition to the challenges mentioned earlier, we must consider the various factors that could impact our model's accuracy. One such factor is the addition of two expansion teams, the Seattle Kraken and the Vegas Golden Knights, which has had a significant impact on the league's overall dynamics. This includes changes in the number of games played, the strength of opponents, and the distribution of wins and losses.
As a result, it is possible that our training data may no longer accurately reflect the current state of the league, which could lead to biased or incorrect predictions. However, we can take steps to mitigate this issue. For example, we could update our training data to include information on the new teams, such as their historical performance in other leagues or the performance of their players. This would provide us with a more comprehensive understanding of the league's current state and help us make more informed predictions.
Alternatively, we could use other data sources or statistical methods to estimate the impact of the new teams on the league as a whole. This would involve analyzing factors such as the teams' performance in other leagues, their draft picks, and their impact on the league's overall competitiveness. By doing so, we can gain a better understanding of the league's current state and adjust our predictions accordingly, ensuring that our model remains accurate and reliable. Overall, we’re satisfied with the outcome of this year’s machine learning NHL projection as an initial experiment. The outcome of the playoffs will add additional data points for comparison and can be used to further improve our model.
Although there are alternatives to time series forecasting, this year’s outcome underscores the importance of having high-quality and accurate data when training a machine learning model.